










Do you ever wonder why you’re getting unhinged responses from ChatGPT sometimes? Or why the heck Midjourney is giving your creations 7 weird fingers? As intelligent as AI is supposed to be, it does produce some pretty unintelligent responses sometimes.
Now, if you’re using GPT to write your next “let ‘em down easy breakup message”, the stakes are low - it doesn’t really matter. But if a core product feature is leveraging AI and your customers depend on super-intelligent perfection, you’re going to want some security and assurances that the outputs are up to scratch. Enter, LangSmith.
Since the launch of HelpHub, we were trying to do things on hard mode when it came to iterating and improving functionality. That is, of course, until the LangChain team tantalized us onto their LangSmith beta. What we didn’t expect was how immediate the downstream improvements were to our flagship AI-powered product.
But is LangSmith robust enough for us to rely on entirely for our LLM-powered QA? Or is it just another nice-to-have feature for our ENG team?
If you’re at the intersection of product, LLMs, and user experience, we’ve just walked so you can run. Time to read on.
- What Is LangSmith?
- LangChain vs. LangSmith: What’s the difference?
- What Are LangSmith Traces?
- Do You Really Need To Use LangSmith?
- How We Use LangSmith at CommandBar: AI-Powered User Assistance
- The Verdict: Are We Betting The House On LangSmith?
- Advice for Product Teams Considering LangSmith
What Is LangSmith?
LangSmith is a framework built on the shoulders of LangChain. It’s designed to track the inner workings of LLMs and AI agents within your product.
Those LLM inner-workings can be categorized into 4 main buckets - each with its own flair of usefulness. Here’s a breakdown of how they all work in unison and what you can expect.
Debugging:
When your LLM starts throwing curveballs instead of answers, you don't just want to sit there catching them. With LangSmith, you can roll up your sleeves and play detective. We use the debugging tools to dive into perplexing agent loops, frustratingly slow chains, and to scrutinize prompts like they're suspects in a lineup.
Testing:
Testing LLM applications without LangSmith is like trying to assemble IKEA furniture without the manual: sure, you could wing it, but do you really want to risk it? Baked into LangSmith is the option to utilize existing datasets or create new ones, and run them against your chains. Visual feedback on outputs and accuracy metrics are presented within the interface, streamlining the testing process for our eng team (we really like this).
Evaluating:
Beyond mere testing, evaluation in LangSmith delves into the performance nuances of LLM runs. While the built-in evaluators offer a preliminary analysis, the true power lies in guiding your focus towards crucial examples (more on how we do that later). As your datasets grow, LangSmith ensures you never miss a beat, making evaluations both comprehensive and insightful. Because "good enough" isn't in your vocabulary, right?
Monitoring:
Think of LangSmith's monitoring as your AI’s babysitter: always vigilant, never distracted, and ready to report every little mischief. It'll give you the play-by-play, ensure everything's in order, and notify you if things get out of hand. We even went a step ahead and piped these flags directly into Slack giving us almost realtime monitoring when our users hit a deadend with chat conversations.
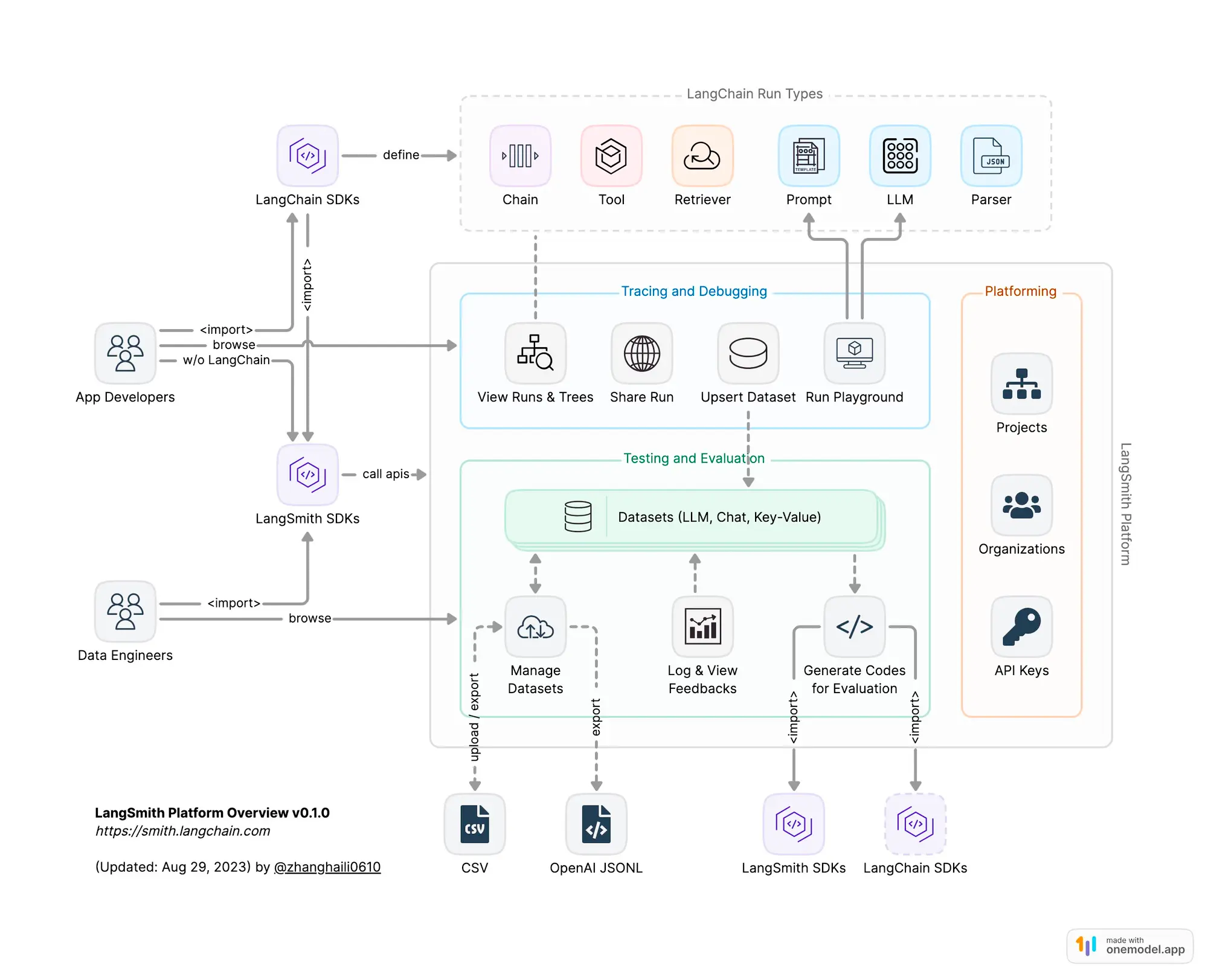
LangChain vs LangSmith: What’s the difference?
While LangChain is the muscle doing the heavy lifting with Chains, Prompts, and Agents, understanding the 'why' behind the decisions LLMs make is a maze we often found ourselves lost in. That's where LangSmith shines, acting as an AI compass built into LangChain, guiding us through the intricate decision pathways and results that our chatbot generates.
"LangChain's (the company's) goal is to make it as easy as possible to develop LLM applications"
said Harrison Chase, co-founder and CEO of LangChain.
"To that end, we realized pretty early that what was needed - and missing - wasn't just an open source tool like LangChain, but also a complementary platform for managing these new types of applications. To that end, we built LangSmith - which is usable with or without LangChain and let's users easily debug, monitor, test, evaluate, and now (with the recently launched Hub) share and collaborate on their LLM applications.”
What Are LangSmith Traces?
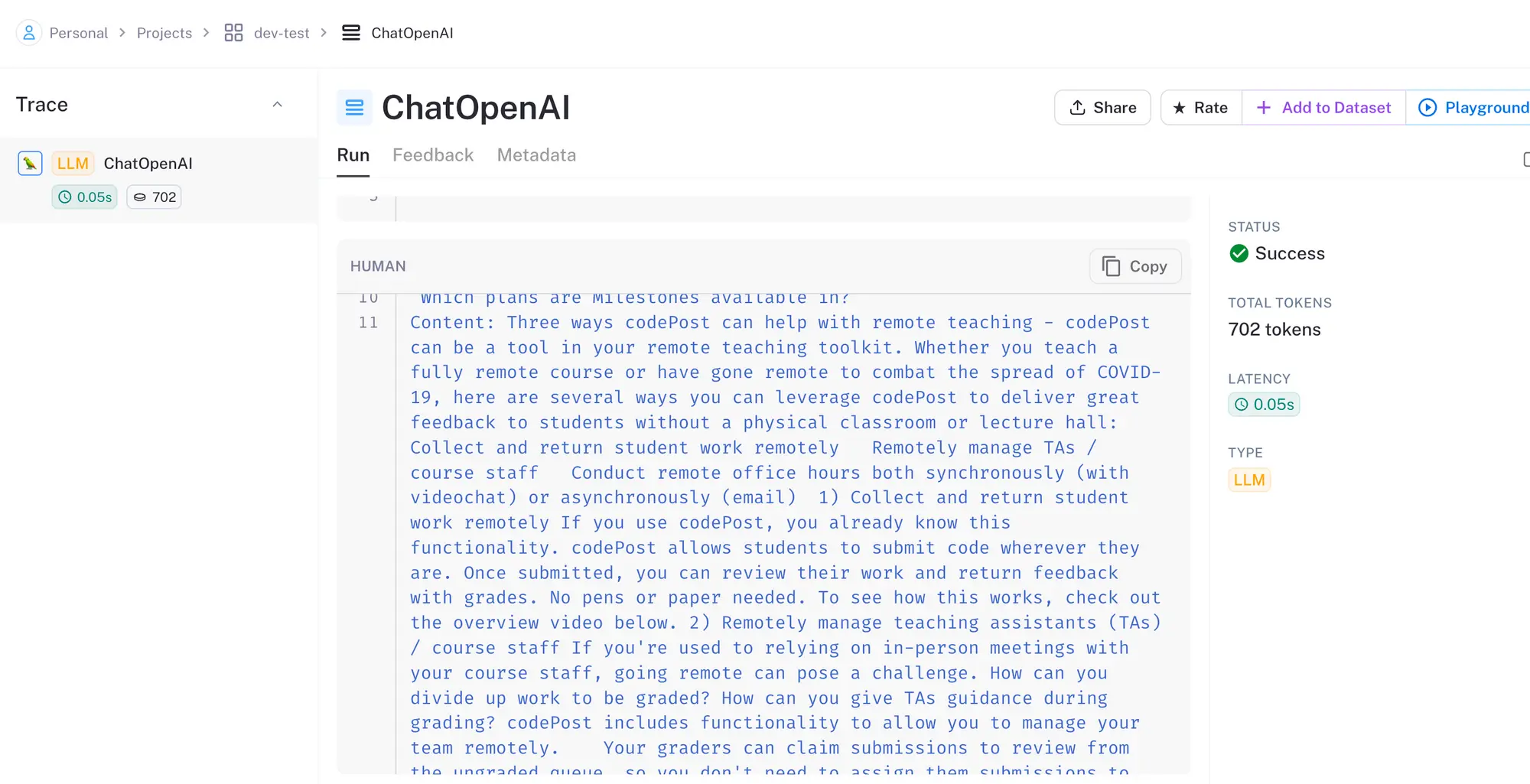
Traces in the world of LangSmith are analogous to logs when programming; they allow us to easily see what text came in and out of chains and LLMs. Think of them as detailed breadcrumbs illuminating the AI's journey. Each trace, like a footprint on a sandy beach, represents a pivotal AI decision. Traces don't merely depict the path taken; they shed light on the underlying thought process and actions taken at each juncture.
Here’s what one of our traces looks like inside LangSmith:
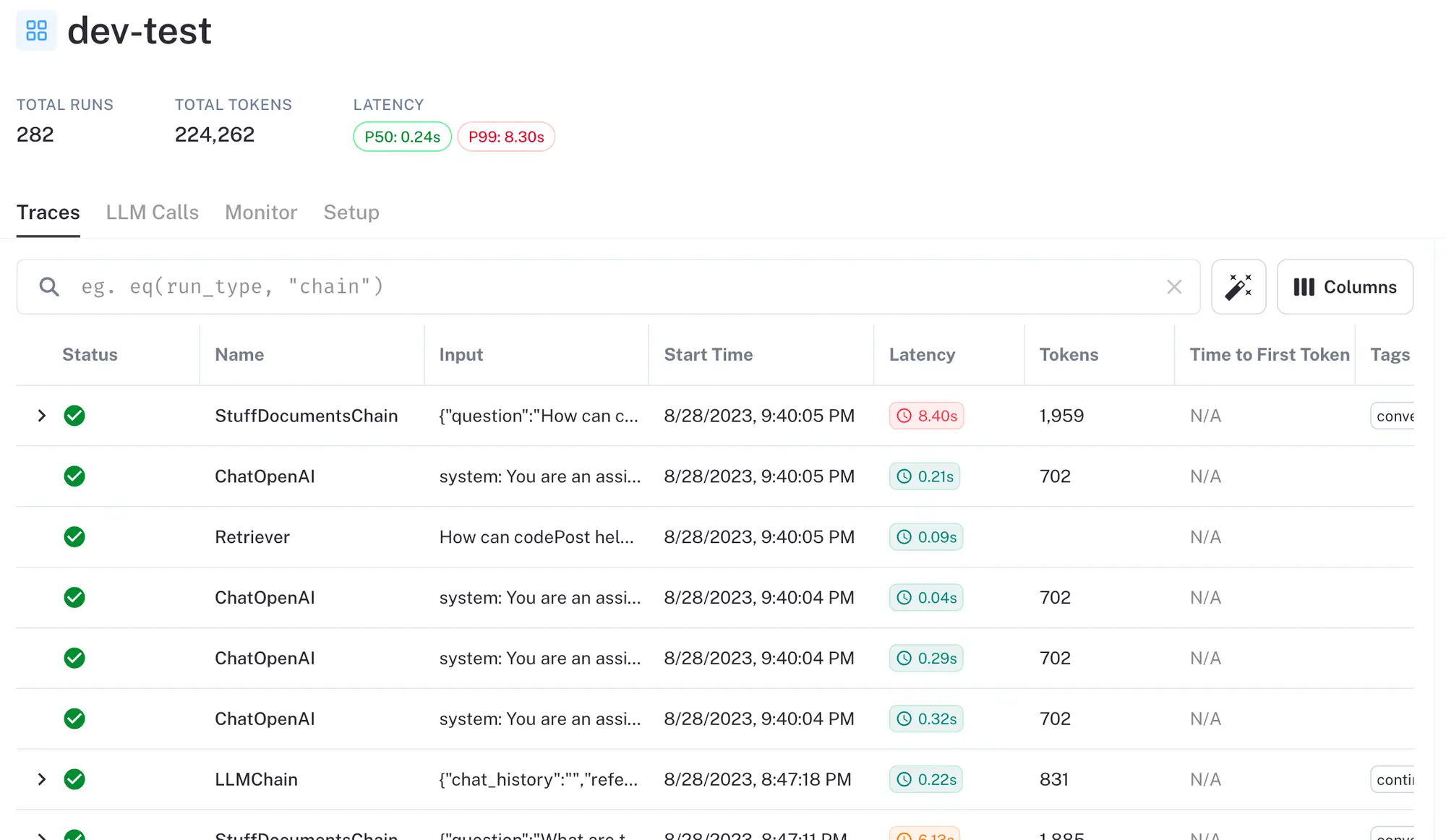
All the individual traces are consolidated into datasets:
Do You Really Need To Use LangSmith?
When generative AI works, it feels like watching a viral “satisfying video” montage - so delightful. But when it doesn’t, it sucks, and sometimes it sucks real bad.
Take it from us, as we integrated AI more heavily and widely across our products, we’ve been more conscious than ever that the quality of the outputs matches the quality and trust that our customers have in our product. G2 review flex here.
Truth is, until we powered up LangSmith, we truly had no way of postmorteming responses from OpenAI or testing how prompt changes, or even upgrading to a new model like GPT-4, would affect the answers.
How We Use LangSmith at CommandBar: AI-Powered User Assistance
We’ve covered a lot of ground so far on how LangSmith works. From here on out, we’re ripping the covers off and showing you what’s under the hood of our HelpHub <> LangSmith setup. To give you a little context, first, let’s dive into what HelpHub is.
HelpHub is a GPT-Powered chatbot for any site. It syncs with any public URL or your existing help center to assist users in getting instantaneous support while circumventing customer service teams or manually screening docs.
While we utilize our own search with ElasticSearch, we rely on LangChain to merge those search results into meaningful prompts for HelpHub. This synergy allows us to search hundreds of docs and sites in milliseconds, source relevant context, compute reasoning, and deliver an answer to our users (with citations!) almost instantly.
It’s through this core integration with LangChain that we’re able to capture traces via LangSmith. primarily to finetune and optimize our chatbot’s functionality and sandbox future improvements for our users.
Accurate AI Responses Are A Necessity, Not A Nice-To-Have
We pride ourselves on offering precise and relevant answers to user queries and that has always been a strong USP for us. However, with the aforementioned challenges of unhinged AI-generated responses not always aligning with user expectations, once we flicked on LangSmith, we took our prototyping and QA from mediocre guesswork to David Blane quality witchcraft.
Since its integration, LangSmith has traced over X0 million tokens for HelpHub (about XM tokens a week!).
Real-world Example of LangSmith In Our Production
Below is an example from Gus, one of our mighty talented LangSmith connoisseurs, caught in one of our traces.
What he’s referring to in the screenshot is the fact that each prompt from HelpHub should reference the source document that it’s referencing when giving users an answer. We do this primarily to legitimize the LLMs response and give our HelpHub customer’s peace of mind that their end users are in fact getting to the help resource they need (instead of an LLM just hallucinating and giving any response it wants.)
From here, we went into LangSmith and saw that the LLM actually returned no source, even though we asked it to. Ideally, the source should be returned on the first line in the “Output” section above the actual answer.
We updated our prompt to be more firm when asking for the sources:
- Previously the snippet in the prompt responsible for this was:
Return the source ID with the most relevance to your answer. - We update that piece of the prompt to:
ALWAYS return the source ID with the most relevance to your answer prior to answering the question.
We then tested everything using LangSmith evals, to make sure that it fixes the issue before pushing to production.
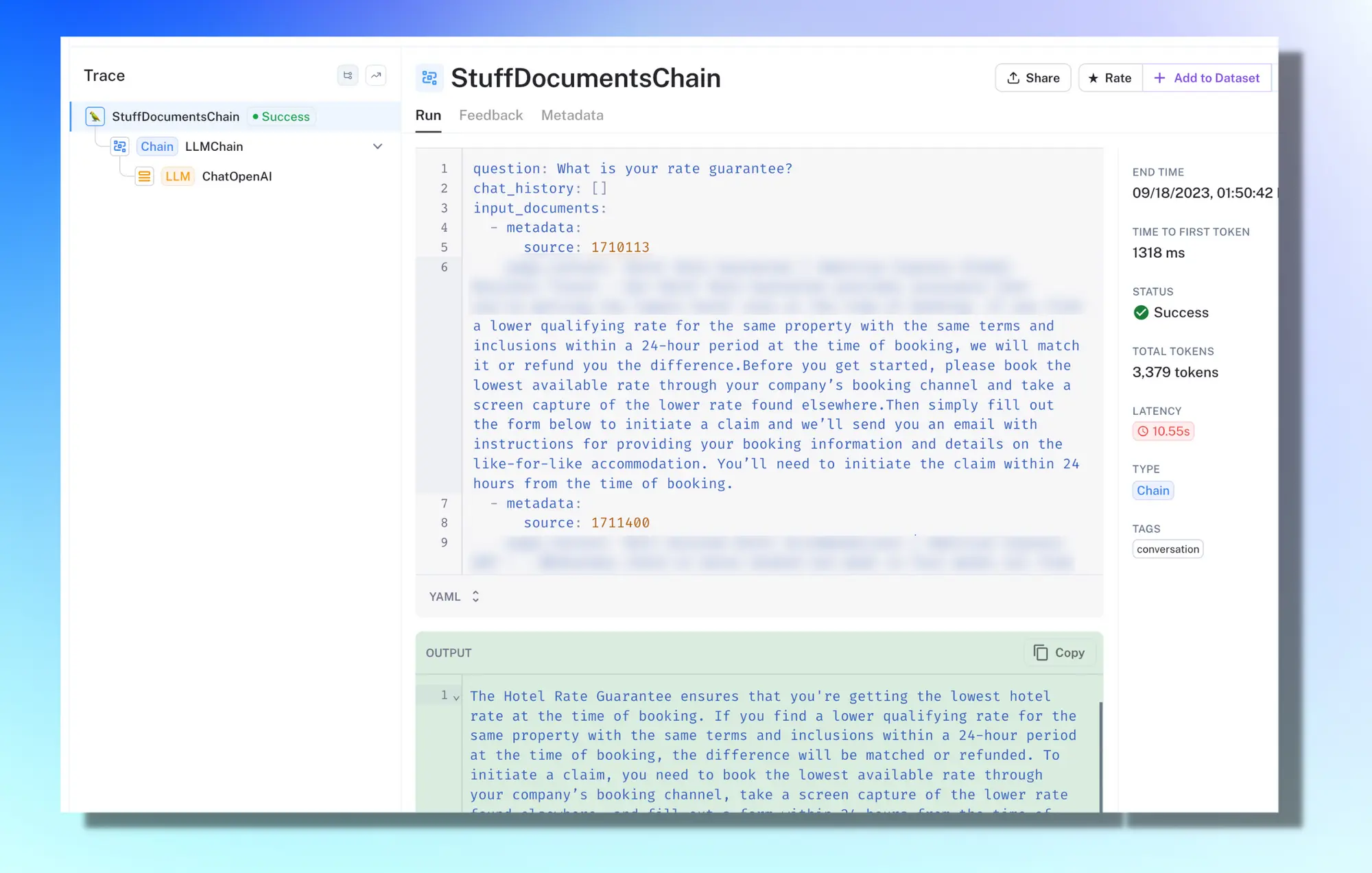
You can now clearly see the citations coming through with the responses in the traces, and we’re good to ship the changes to the prompt to prod.
The Verdict: Are We Betting The House On LangSmith?
When a product like LangSmith comes along, it can feel really natural to default to the path of least resistance and offhand all responsibility. As we start to add additional functionality to HelpHub, there’s an inherent risk that GPT is going to lead users astray, and that’s just not an option we’re willing to entertain.
So, in short, yes, we are putting a lot of trust right now in LangSmith and scaling our prototyping and debugging rapidly. The systems we’re building internally have already been instrumental in improving user experience, and as you’ve read earlier, many of these insights and improvements have come directly from those real-time traces from users chatting with HelpHub in the wild.
Leveraging User Feedback For Improvements:
We believe that every piece of user feedback, whether positive or negative, is a goldmine of insights. And with LangSmith's help (plus a little ingenuity on our side), we've turned these insights into actionable improvements.
Here's how our feedback loop works:
- Real-time Feedback Collection: As users interact with HelpHub, they have the opportunity to provide feedback on the AI-generated responses, signaling with a simple "thumbs up" or "thumbs down".
- In-depth Analysis with LangSmith: Instead of just collecting feedback in the form or positive or negative signals, we delve deeper (particularly for the negative signals). Using LangSmith, we’re able to attribute each signal to an individual trace. In that trace, we can map the exact sequence of steps the model took to generate that response. We essentially replay GPT's thought process and LangChain’s actions, giving us the insights into what went right and where it veered off track.
- Categorizing Into Datasets: Central to our refinement process is LangSmith's use of dynamic datasets. We maintain multiple datasets, each tailored to different query types and user interactions. These datasets are essentially compilations of identical states of our environment at the time the trace was captured. This ensures that when there's an update to the prompt or LLM, a new dataset starts to compile those traces, preventing any contamination.
- Automating ENG-team Signals: When a user provides feedback, say a thumbs down, it's immediately flagged to our team via Slack. We built this little snippet to help the team screen traces and prioritize the ones that need attention right away.
- Iterating Quickly: We rigorously review the feedback, analyze the corresponding traces, and then, based on our insights, make informed adjustments to the model's role, prompts, or configurations to try and curb whatever jankiness was happening. This iterative process ensures our AI chatbot is continually refining its understanding, resonating more with user needs, and exceeding expectations over time.
By combining granular AI insights through LangSmith with user feedback, we’ve created a pretty tight loop of perpetual improvement with HelpHub. This was such an important unlock for us as we build in tactical functionality to our AI.
Advice for Product Teams Considering LangSmith
When you're in the thick of product development, the whirlwind of AI and LLMs can be overwhelming. We've been there, boots on the ground, making sense of it all. From our journey with LangSmith and HelpHub, here's some hard-earned wisdom for fellow product teams.
Start with Data, and Start Now:
AI thrives on data. But don’t wait for the 'perfect' moment or the 'perfect' dataset. Start collecting now. Setting up LangSmith takes literally 5 minutes if you’re already using LangChain. Every bit of data, every interaction, adds a layer of understanding. But, a word to the wise: quality matters. Make sure the data reflects real-world scenarios, ensuring your AI resonates with genuine user needs.
- Dive Deep with Traces: Don't just skim the surface. Use LangSmith's trace feature to dive deep into AI decision-making. Every trace is a lesson, a chance to improve.
- Experiment with Prompts: One of LangSmith's standout features is its ability to test a new prompt across multiple examples without manual entry each time. This makes it incredibly efficient to iterate on your setup, ensuring you get the desired output from the AI. Note, in addition, the Playground is also an amazing tool to dig around with for testing prompts and adjustments to traces too.
- Lean on the Community: There's a whole community of LangSmith users out there. Swap stories, share challenges, and celebrate successes. You're not alone on this journey.
- Stay on Your Toes: AI doesn’t stand still, and neither should you. Keep an eye on LangSmith's updates. New features? Dive in. Test, iterate, refine.
Conclusion
After diving deep with LangSmith's traces, experimenting with prompts, testing, and iterating on our LLM environment, here's the real talk: LangSmith isn't just a tool for us - it's become a critical inclusion in our stack. We've moved from crossing our fingers and toes hoping our AI works to knowing exactly how and why.
So, to our fellow AI product people trailblazers, dive into LangSmith. You’d be silly not to if you’re already using LangChain!










